刚刚过去一个多月,智谱才发布GLM 5.0,没想到昨晚又突然推出改进版GLM 5.1。这个版本依旧主要致力于AI代码能力,并且跑分成绩提升十分显著。
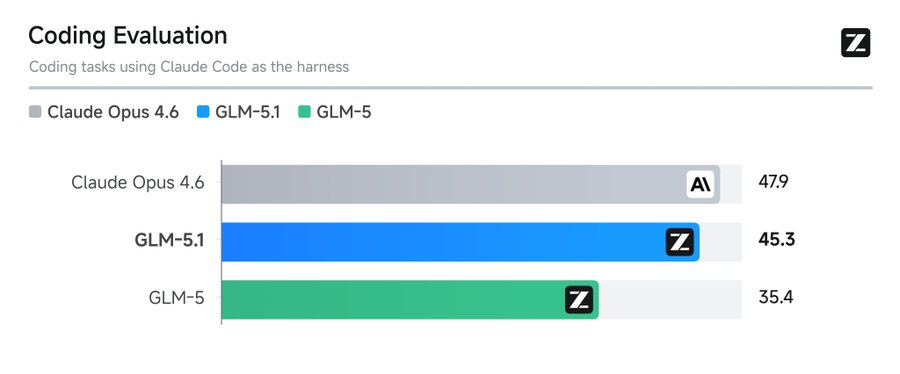
查看官方给出的相比数据,GLM 5.0于评测里获得35.4分,然而GLM 5.1猛地窜至45.3分。仅仅一个多月就提升将近10分,增长幅度超过30%,这般速度着实令许多程序员感到诧异。
与国际最强编码模型差距不到3分
当下,在全球范围内受到公认的、最为强悍的编码大模型为Opus 4.6 ,GLM 5.1的得分相较于它仅仅少了2.6分。这表明二者的编程能力已然极为相近 ,国产模型于代码生成这个高难度任务方面正处于快速追赶的状态。
应当清楚,就在去年的这个时段,国产进行编码的模型跟顶尖的水准之间所存在的差距是超过15分的。如今这个差距不到3分,对于日常开展的编程任务而言,用户所拥有的体验或许早就难以分辨出显著的高低差异了。
价格优势极其明显
Opus 4.6是如今最强的编码大模型,然而它也是最贵的那个。为数不少的程序员在私下里吐槽称用不起,特别是个人开发者以及中小企业,每个月的API调用费用有可能超过一万块钱。
智谱的GLM系列模型,有Lite版,有Pro版,还有Max版,其价格只是Opus 4.6的几分之一 ,对于有高频调用编码能力需求的用户而言,这样的成本差距意味着一年能省下好几万块钱。
面向所有GLM Plan用户开放
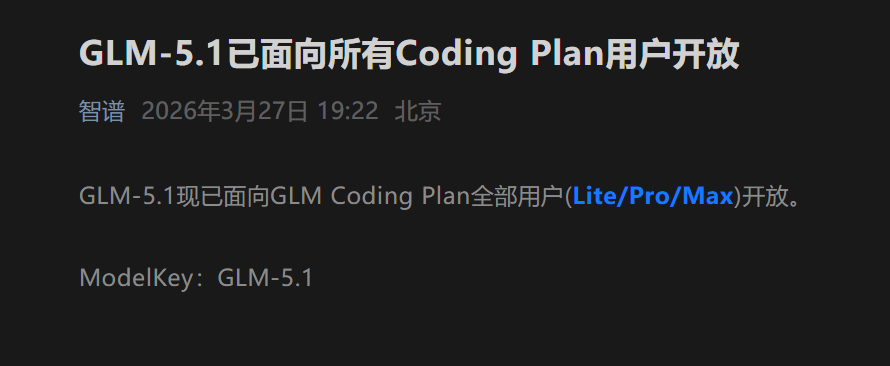
现在,GLM 5.1已对GLM Plan的所有用户开放,无论你使用的是Lite版本,还是Pro版本,亦或是Max版本,均可直接使用这个改进版,这表明免费用户也能够体验到近乎顶级的代码生成能力。
详细来讲,Lite版的用户,尽管其调用的次数存在局限性,然而对于日常的小型代码任务而言,那是已然足够的。而Pro用户以及Max用户,能够以更高的频率去加以使用,这是契合那些需要进行批量代码生成或者处理复杂项目的开发者的需求的。
跑分不代表一切
即便 GLM 5.1 的跑分呈现出颇为好看的态势,然而其实际运用效果却仍得打上一个有待商榷的问号,跑分评测一般所采用的是标准测试集,可真实的编程场景却是各式各样、差别极大,其中涵盖了框架版本、依赖环境、业务逻辑等诸多不同的变量。
有一些模型,在跑分一事上展现出不错之表现,然而一旦碰到复杂的实打实项目就原形毕露了。比如说,处理那种超过500行的代码文件,又或者是理解项目内部多个文件的依赖关系,此等种种方才是对编码模型真实能力予以考验之处。
国产模型仍有进步空间
在编程领域,国外大型模型积累的数据量,比起国内要多很多。从GitHub之上供众人查看的代码库,到Stack Overflow这个平台的有人提出并得以解答的问题数据,再到各种各样的技术方面的文档,国外模型展开训练之时能够接触到的语言材料,更加丰富,而且也更加规范。
除此之外,算力规模同样是一种现实存在的差距,训练以及运行大模型需要诸多GPU,国外头部公司的算力集群规模是国产模型的好几倍乃至数十倍,这表明在模型迭代速度和推理性能方面,国产模型尚需时间去追赶。
程序员的实际体验才是关键
究竟GLM 5.1好不好用,最终得看广大程序员的实际反馈,这一点很关键。跑分提升了30%,这无疑是件好事,不过呢,如果生成代码的bug率没有显著下降,而且对特定框架的支持依旧不够理想,那么这种提升就会大打折扣。
过去的几个月当中,好多国产模型都声称自身的编码能力有了大幅的提升,然而实际测试之后,有的模型在生成Python代码以及JavaScript代码的时候还算可以,可是转换到Rust语言或者Go语言就显著不达标了,GLM 5.1需要在多种语言以及框架之上都论证自身。
你认为GLM 5.1跟Opus 4.6于实际编程里差距是不是很大呢,欢迎在评论区域分享你的实测感受,同样不要忘记点赞并转发以便让更多程序员瞧见这篇文章。
© 版权声明
文章版权归作者所有,未经允许请勿转载。


